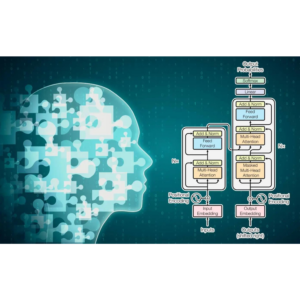
Large Language Models (LLMs) such as GPT-3, PaLM, and GPT-4, and products built on them, such as ChatGPT, not only have revolutionized natural language processing, but also are starting to have a profound impact on society and humanity. These models, however, are large-scale complex systems, and little is known about their inner workings. Toward a better foundational understanding of LLMs, this project aims to rigorously study several fundamental questions: (1) Emergent behavior. What gives rise to the emergent capabilities of LLMs which are not explicitly encoded in their training objectives? (2) Knowledge representation. How do LLMs store knowledge internally, and how is information processed from layer to layer? (3) Interpretability. Which components in the model or which training datapoints are responsible for a particular model prediction? We will study these questions using both empirical and theoretical approaches.
People

Wei
Hu
CSE
Engineering

Joyce
Chai
CSE
Engineering
Funding

Funding: $30K (2023)
Goal: This project will enhance our understanding of large language models at a fundamental level.
Token Investors: Wei Hu and Joyce Chai
Project ID: 1129